Introduction to Service Discovery
So, here I am going to explain you in detail about the Service Discovery using DNS as of Kubernetes 1.3. DNS is a built-in service launched adamantly using the addon manager. Before 1.3, we had to enter some commands and now it is already launched automatically.
- The addons in the Kubernetes are in the “/etc/Kubernetes/addons” directory on the master node.
- The DNS service can be used within pods to find other services running on the same cluster.
- Multiple containers within one pod do not need this service, as they can contact each other directly.
- A container in the same pod can connect to the port of other container directly using the “localhost: port”.
- So, if you have a webservice and database service then the webservice can connect the localhost and then the port of the database and it will be able to access the database within the same pod.
- If you want to connect from a webservice in one pod to a database service in other pod, then you will need “Service Discovery” because you cannot just access the other pod.
- To make DNS work, a pod will need a service definition. So only when you create a service for a pod really becomes accessible and Service Discovery will work.
Let’s take an example of how one app could reach another app using DNS.

- On the left, you have Application-1, a container in a pod and a service for that pod. A service is at “app1” and has IP address 10.0.0.1. Then, on the right we have Application-2, a container in a pod and has another IP address 10.0.0.2 for “Service:app2”.
- If you execute commands on the container of pod one for instance host of one service, the name of the service, then you would get the IP address back 10.0.0.1. This is the service discovery in action. You only need the name of the service to find the IP address of that service.
- If “app-1” wants to contact “app-2”, it can do a DNS lookup on “app2-service” and it will get IP address 10.0.0.2. This is only going to work if both applications are in the same name space.
- The standard namespace that we have been launching in is the default namespace because we have not really specified a name space. Default stands for default namespace. Pods and services can be launched in different namespaces to logically separate our cluster. Default is “default1”.
- There is also a kubesystem where the Kubernetes services run in. If you want to specify a namespace, then you just do a DNS look up of “app2-service.default”.where default is the namespace. If you want to do a look up on the full hostname, the full hostname is actually the “[The name of the service]. [namespace].[svc].[cluster].[local]”.So, in our case it is app2-service.default.svc.cluster.local has address 10.0.0.2. So, this is how one application in one pod can access another application in another pod.
Note: These requests here are always on the “A” type which is resolving from a host to an IP address. There is also an “SRV” type if you want to know the port number. So, here we just have the IP address, but it is also possible to get the port number.
How does DNS work?
So, let’s say we have a pod on the left with a container. We can start this container using “kubectl run” on busybox.[busybox is an image that bundles Unix utilities and provides single executable file with all unix utilities and buxybox image can be run in Linux and other env. As well ]
- I am going to run the busybox image and this will give us a shell. We can use “cat” to show the content of file “/etc/resolv.conf” , then you can see the name server points to 10.0.0.10–>this is the DNS server. And the DNS server is “kube-dns” running in another pod, exposed as a service, with IP address 10.0.0.10.
$ kubectl run -I –tty busybox –image=busybox –restart=Never – sh
Waiting for pod default/busybox to be running, status is pending, pod ready:false
If you do not see a command prompt, try pressing enter
/# cat /etc/resolve.conf
- The reason why I did not see it when I did “kubectl get pods” , because it runs in another namespace. But if you would do “—namespace=kube-system”, and then when you run the command “kubectl get pods”, then you would see that are pods running anytime when Kubernetes is running.
- The reason why we can use the service name, or servicename.default, orservicename.svc.cluster.local, then you can see here with the search in Linux. When you look up a DNS name, this can be automatically added.
“search deafult.svc.cluster.local”
“Nameserver 10.0.0.10 “
- So, if you just do a lookup of the service name, then actually it will do a DNS request of servicename.default.svc.cluster.local. So, this is how it works. DNS resolving can help us to do Service Discovery.So, Now I am going to run a web-app deployment and I am also going to run separate service and then you can see how by using just the DNS names, our web-app will be able to find the database which is the other side of service.
Demo Service Discovery
I have already created a folder Service-Discovery. I am going to create few resources again. I have created a file called “secrets.yml”. I have stored here sensitive data password, rootPassword , user name and the database. [For storing, managing passwords or any sensitive or secure information we use Kubernetes “Secret”. Secret gives us more flexibility than placing the passwords in a Pod.]
- Secrets.yml file:

- I am going to use rootPassword here rather than using separate user name and password.Now run the below command for secret creation.
![]()
- Now I am going to create the database pod. So, for that I have created “database.yml” file as below screenshot:
- databse.yml file:
The name of the database container is “mysql:5.7”. The name is database. containerPort is 3306. I have specified “MYSQL_ROOT_PASSWORD”.

- Also, I have created a service which is going to expose a node port, the random node port. For creating the service, I have created a “database-service.yml” file as below screenshot:
- databse-service.yml file:

- I executed the below command for database service creation Then I have also created a “helloworld-db.yml” and a service.
![]()
- Now, I have created deployment yaml file as below:
- helloworld-db.yml file:

- So, in this deployment kind file, 3 replicas of “k8s-demo”. I named it “helloworld-db”. This image has an “index-db.js” file. If you specify command “node” in the index-db.js rather than using “npm start” which is executing node “index-db.js”(This Js file you can write only for doing some simple db specific operation in database for ex: inserting and deleting a value from a table). I can override this in the above yaml file.
- I can execute different command on my image. Port name is “nodejs-port :3000”. Also, I have added environment variable in yaml file. rootPassword I am taking from secretKeyRef which we already have created using secret.yml file.
- This is going to connect to our database and is going to use the host “database-service”. So, this will only work if the DNS resolving works because my database service is named as “database-service”. The value of MYSQL_HOST needs to resolve to the IP address of our database-service. Then our app will be able to connect to our database. Let’s try this out.
- I am going to do a create of this “helloworld-db.yml” and “helloworld-db-service.yml”.
“helloworld-db-service.yml” file:
This service is very generic and is just going to expose our “helloworld-db” app.

- Now, to find the URL of the “helloworld-db-service” that we will connect to later, please execute below command:
![]()
- The URL output we will get as : http://192.168.99.100:30518 .So, first we will check all the pods are running or not using “kubectl get pods”

- So, we have one database which is just a pod and then we have 3 pods for deployment. All of them are running. Now we have to check the logs of the pod to see whether we are able to connect to the database or not. To check the logs, execute the command and you can see the logs that would say that connection to db is established.
![]()
- So, our node js app is able to connect to the database using the credentials. Now you can test the app using the app url with curl command: “curl http://192.168.99.100:30518”.
- So, here we successfully connected to the database-service. Our web-app is able to discover the service and connect to the database. This is because DNS resolving works here. You can do “nslookup” in busybox to check whether our helloworld-db-service can resolve. Kube-dns answers with helloworld-db-service at 10.0.0.52. Similarly, you can look up the database-service using nslookup.
ConfigMap Overview
- Configuration Parameters that are not secret, not like credentials, can be put in a ConfigMap. The input is again a key value pair. Just like credentials, we have user name and password. Here we have another key-value pair. The ConfigMap key-value pairs can be read by the app using:
- The environment variables
- Container Commandline Arguments in the pod configuration.
- Using volumes.
- A ConfigMap also can contain full configuration files where the value is actually a configuration file and not just a short string. For example, A full configuration file can be a web server configuration file. This file can be mounted using volume where the application expects its config file. This way you can inject configuration settings into containers without changing containers itself.
- Suppose if you have to use the nginx container and if you want to change the configuration and you inject that configuration file as a volume in that image. You did not change the image at all here. Just the configuration file is different, and you can run any container with the configuration that you want.
- To generate a ConfigMap using files where we first put data in our file, you can use the following commands: “$ cat < app.properties”
$ cat <<EOF>
app.properties
driver = jdbc
database = postgress
otherparams = xyz
EOF
$ kubectl create configmap app-config –-from- file=app.properties
- The above command will just get the data that you write on terminal and put it in app.properties until you write the letter EOF. The next commands are key value pairs of the properties file. This file we are going to read using “kubectl create configmap app-config-–from-file =app.properties”. This is very simple config map, where we just have avery short string.
How ConfigMap Works
- We can create a pod that exposes the ConfigMap using a volume or as environment variables. Here, I am going to show you how ConfigMap works. I have created a configuration file for Nginx. I have also created a configuration file reverseproxy.conf as below:
reverseproxy.conf file:

- This configuration is going to make sure that our nginx is listening on port 80. The server name is localhost. Whenever it gets a hit, it is going to forward its request to the URL as above: http://127.0.0.1:3000( In this URL, hello worldNodejs is running on port 3000).
- I am going to create the nginx-config ConfigMap from the file “reverseproxy.conf” using below command:
$ kubectl create configmap nginx-config –from-file = configmap/ reverseproxy.conf
- Now, to check if config map is created or not then execute command:
$ kubectl get configmap
- Then, you will get the output as below:
![]()
- Now, we can get the configmap output in the yaml format using the command and then you will get the below output in yaml file view:
$ kubectl get configmap nginx-config -o yaml
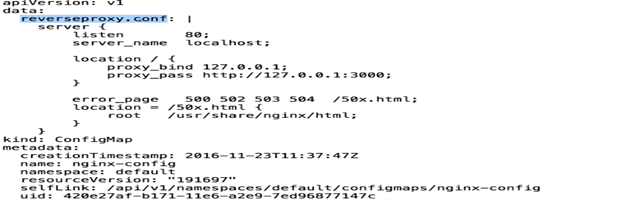
- So, here inside the “data:” field, we have the key “reverseproxy.conf” in the ConfigMap named as “nginx-config”. Now, let’s see my pod configuration that I am going to launch at nginx.yaml file. The file looks like below:
nginx.ymlfile:

- Here in the above image, you can see that the pod name I have given is “helloworld-nginx”. I have configured two containers one is going to be the nginx container and other is “k8s-demo” container. One is running on container port 80 and other is running on 3000. My nginx has a volume mount with the name “config-volume”and the mount path is “etc/nginx/conf.d”. This is a predefined config path where nginx this image will be looking for its configuration.
- The config-volume also defined in the above will look for the ConfigMap named as “nginx-config” , that we have just created earlier for the key “reverseproxy.conf”. And it is going to put that file with the same name “reverseproxy.conf”.
- Now, let’s execute the nginx.yml file with the below command:
$ kubectl create -f configmap/nginx.yml
- Now, create a service nginx-service.yml. This service is just going to expose a NodePort. Similar service yaml file I have created in my earlier example please refer. Now execute the yaml file with the command:
$ kubectl create -f configmap/nginx-service.yml
- Now, to find the URL where the “helloworld-nginx-service” is running, please execute the below command:
$ minikube service helloworld-nginx-service –url
- The output I received: http://192.168.100:31264
- Then you can check if our helloworld-nginx pod is running or not using “kubectl get pods” command.So, now I am going to execute Curl command to hit the URL like below:
$ curl http://192.168.99.100:31264:31264 -vvvv//Here -vvvv is for increasing the verbosity. - Now with the above command, we can see the output as who is entering to these requests as below:

- You can see in the above image the server nginx/1.11.5, is answering to our request and it is forwarding the request to our other container in this pod. This is how you can put nginx reverse proxy in front of nay web app. In my case it is NodeJS App.
Ingress Controller
Ingress is a solution available since Kubernetes 1.1 that allows inbound connection to the cluster. It is just an alternative to the external Load balancer and the node ports. Ingress allows us to easily expose services that need to be accessible from the outside to the cluster. With ingress we can run our own ingress controller or basically a load balancer within Kubernetes cluster. There is default ingress controller available from Kubernetes or we can write our own custom controller.
Please see the below diagram to understand how this works:

If you connect from internet on port 80 or https on port 443, then you are going to be hitting this ingress controller. You should configure what pod needs to be handling the connections from the ingress controller. You can use nginx ingress controller that comes with Kubernetes.
That nginx Controller is going to distribute the traffic to your services. So, we can have application-1 that can receive traffic from ingress controller and application-2. Which one is going to receive traffic is going to be based on the rules that you define in the Ingress object.The ingress rule can be like if you connect to the host-x.exmple.com then you go to pod 1. If you connect to host-y.example.com, then you go to pod-2 i.e. the application-2 in our case. So, here rules are based on the host. You can create rules based on the path as well.
Demo: how Ingress controller Works
Here, I am going to use nginx Ingress Controller i.e. the existing one:
- Here, it is a replication controller. So, if this one would crash, then it would be automatically relaunched. It is an image coming from a google controller. In the below file, we have a “readinessProbe” which is to know when the container is ready and then we deploy it.
- “LivenessProbe” is to periodically check whether our container is still healthy. Then we are going to specify a pod name in this file. We are going to run the pod on port 80 and 443. This ingress controller is really working on standard HTTP port and HTTPS port.
- nginx-ingress-controller.yml file

Now, I am going to define my ingress rules in my ingress.yml file as below:
- ingress.yml file:

- In the above image, you can see that these are the hosts : helloworld-v1.example.com and v2.If it does not match to these two hosts then go to the default service i.e. “eachoheaders-default”Now, we will create the ingress with below command:
$ kubectl create -f ingress/ingress.yml
- Then will create the controller using below command:
$ kubectl create -f ingress/nginx-ingress-controller.yml
- Now, we are going to create 3 services using below commands:
$ kubectl create -f ingress/echoservice.yml
$ kubectl create -f ingress/helloworld-v1.yml
$ kubectl create -f ingress/helloworld-v2.yml
- So, these are the Java development services that we are going to access. The only thing difference between the v1 and v2 app is that in v2, I am asking for image version k8s-demo2 and the other one(helloworld-v1.yml) is same file only one change i.e. the standard image version.
helloworld-v2.yml file:

- Now, let’s see if the pods are up or not using “kubectl get pods command”. Now to get the IP address of our cluster, we can execute command “minikube ip “. If you are testing in AWS, then you have the IP address in EC2 console. You just might to have to change your security groups to make sure that those ports are open. Now I am going to curl the cluster IP(192.168.99.100) like below with the host:
$ curl 192.168.99.100 -H ‘Host: helloworld-v1.example.com’ (-H for passing header).
- So, this curl command will go to real DNS name in your browser. We will get the output as “Hello World!”. Similarly, you can try for another host name v2.So, this is now the ingress controller works. It is in Beta stage now and still will become stable.
Conclusion
Through this blog you have got real-time example of advance Kubernetes topics: Service Discovery and ConfigMap. The importance and advantages of using service discovery, ConfigMap and Ingress controller have been clearly explained in this article. Please try to execute the demo yourself so that you would understand the architectural flow pattern in the era of cloud.








